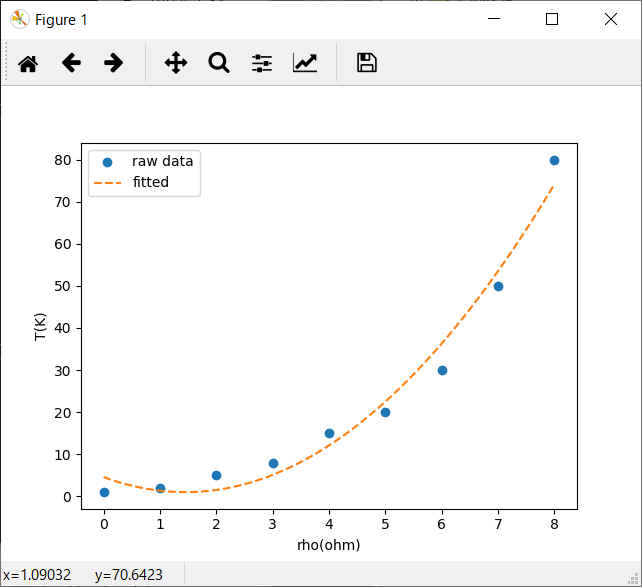
numpy.polyfit()を用いて多項式最小二乗法、グラフにプロット
import sys
起動時引数を取得するため、sysモジュールをimport
import csv
from pprint import pprint
from math import sqrt
sqrt()を使えるようにmathモジュールからimport
import numpy as np
from matplotlib import pyplot as plt
#=============================
# 大域変数の定義
#=============================
infile = 'data.csv'
fitrange = [0, 10.0] フィッティング範囲を指定する変数
argv = sys.argv
sysモジュールを使って起動時引数を取得する
print("argv=", argv)
起動時引数 argvの最初の要素
argv[0]
はpythonスクリプトのパスであることを確認する。
そのため、起動時引数の要素数 len(argv) は 1以上。
if len(argv) >= 2: 起動時引数が与えられると、argvの要素数は2以上になる
fitrange[0] = float(argv[1]) 引数が与えられたら、フィッティング範囲下限とする
if len(argv) >= 3:
fitrange[1] = float(argv[2])
引数が2つ与えられたら、
2つ目はフィッティング範囲上限とする
print("fitting range: ", fitrange)
#=============================
# csvファイルの読み込み
#=============================
i = 0
x = []
y = []
with open(infile, "r") as f:
reader = csv.reader(f)
for row in reader:
if i == 0:
header = row
else:
xi = float(row[0])
if fitrange[0] <= xi <= fitrange[1]:
xiがフィッティング範囲にあるときのみ,x,
yリストに追加
x.append(xi)
y.append(float(row[1]))
i += 1
print("header:", header)
print("x:", x)
print("y:", y)
#=======================================
# numpy.polyfit()による多項式最小二乗
#=======================================
print("polynomial fit start:")
ret = np.polyfit(x, y, deg = 2, full = True) full =
Trueを指定すると、
戻り値はいろいろな情報を含んだリストになる
print("ret=", ret) 戻り値を確認
ai = ret[0]
戻り値の最初は、最適化したパラメータのリスト
residual = sqrt(ret[1][0] / len(x)) 2つ目の戻り値は残差二乗和。
解析データが複数の場合もあるので、リストで与えられる。
最初の残差二乗和を使って平均平方根に変換。
print(" lsq result: ai=", ai)
print(" residual=", residual)
#=======================================
# グラフをプロット
#=======================================
xmin = min(x)
プロット範囲を決めるため、min(),
max()を使って元データの上下限を取得
xmax = max(x)
ncal = 100
フィッティング結果を滑らかに表示するためのデータ点数
xstep = (xmax - xmin) / (ncal - 1) フィッティング結果を計算する際のxメッシュ間隔
xc = [] フィッティング結果のx値のリスト
yc = [] フィッティング結果のx値のリスト
for i in range(ncal): フィッティング結果のプロットデータxc,ycの計算
xi = xmin + i * xstep
yi = np.poly1d(ai)(xi)
xc.append(xi)
yc.append(yi)
#元データを
〇、線なしでプロット。labelで指定した文字列が 凡例
(legend) として使われる
plt.plot(x, y, label='raw data', marker = 'o', linestyle = 'None')
#フィッティングデータを破線でプロット
plt.plot(xc, yc, label='fitted', linestyle = 'dashed')
#CSVのheaderの最初をx軸ラベルに設定
plt.xlabel(header[0])
#CSVのheaderの2つ目をy軸ラベルに設定
plt.ylabel(header[1])
#判例をプロットするように指定
plt.legend()
plt.show()